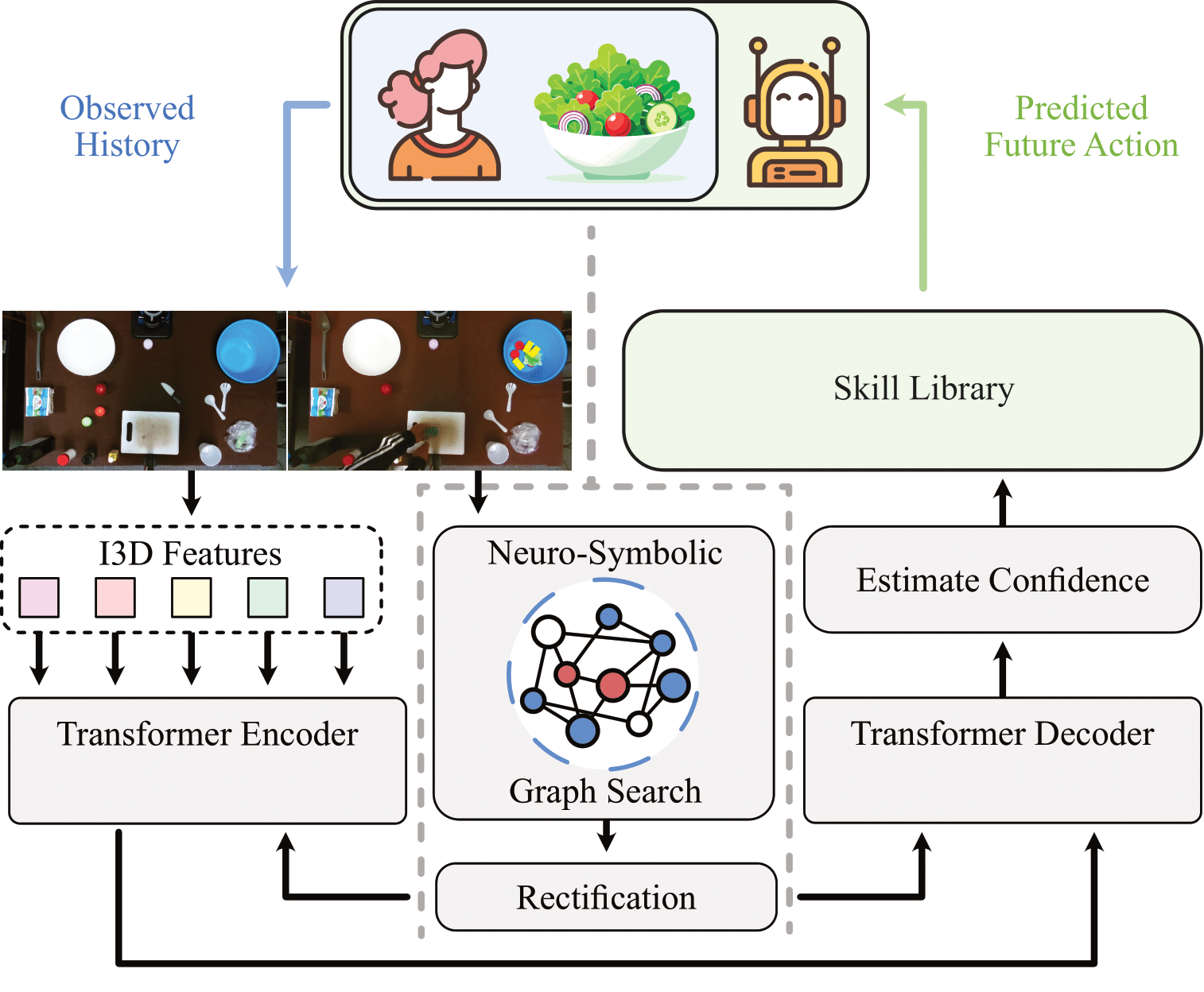
Neuro-Symbolic Short-Context Action Anticipation
We employ a graph propagation approach to discern relevant affordances linked to each object in the scene and the necessary tools to afford them in the desired manner. The representations for these objects and affordances are then used to adjust attention for visual features in both the transformer encoder and decoder. Subsequently, we derive a sequence of actions predicted to occur in the future part of the video. The robot executes actions for which our model expresses sufficient confidence, utilizing the skill library (outlined in the section below) to assist the human.
Human-Robot Collaboration Demonstration
We present a sample video showcasing the humans robot collaboration facilitated by our system. In this scenario, a robot observes human actions through a top-view RGB camera. It employs our novel neurosymbolic action anticipation framework, NeSCA, to predict the sequence of actions that the human will most likely do. Subsequently, the robot assists the individual by executing actions it is confident about based on its predictions.
Skill Library
We perform the actions anticipated by NeSCA by utilizing a pre-defined skill library {S0, S1, S2 ... Sm} where each high-level skill Si corresponds to a specific sequence of low-level control inputs. The skills in the library are broadly categorized into three "grasp types": a top-down grasp, suitable for pick-and-place actions with items like vegetables; a sideways grasp, ideal for picking up and pouring objects such as olive oil or vinegar bottles; and an aligned grasp, designed for handling oriented tools like knives and spatulas. The aligned grasp feature is specifically engineered to bring and hand over tools to a human collaborator. In this process, the robot first brings the instructed tool near the potential area of use for easy accessibility.
Add Vinegar

Hand Over Spatula

Pick & Place Tomato

Add Pepper

Pick & Place Cheese

Add Dressing

Pick & Place Cucumber

Add Salt

Dummy Kitchen Action Anticipation Dataset
We open-source the collected trajectories in our real-world kitchen setup. This dataset promotes the application of action anticipation from videos for the purpose of real-world human robot interaction.
Sample videos from the dataset

